0. 생각 정리
-. 프롬프트 러닝(학습 데이터 없이, 말로만 학습 하는 기법)의 베이스가 되는 논문 중 하나
-. CoCoOp(CoOp을 확장한 논문) 전에 잠시 정리
1. 논문 요약

1) 일반적인 CLIP 평가 시
- A photo of apple, A picture of apple 등 정형화 된 Text 문장을 넣어 평가(embedding 되어 77 길이로 변환되어 사용됨)
2) CoOp의 경우
-. V1, V2, V3 ......, [apple] 과 같이 "A photo of" 가 아닌 학습가능한 vector를 넣어 text encoder를 통과 시켜, 이미지 feature와 임베딩 시킴.
2. 장단점 비교
-. 생각에 미학습된 이미지에 대한 정확도가 떨어질 수 밖에 없음(Overfitting) --> CoCoOp으로 확장
(이미지에 대한 token을 추가 추출하여, contect Vector에 추가하는 방향으로 정확도 향상)
-. 하나의 Class에도 수 ~ 수십개의 프롬프트가 생길 수 있지만, 이를 Vector를 통해 자동 획득 가능
(Few shot으로도 충분한 학습가능)
3. 참고
CoCoOp
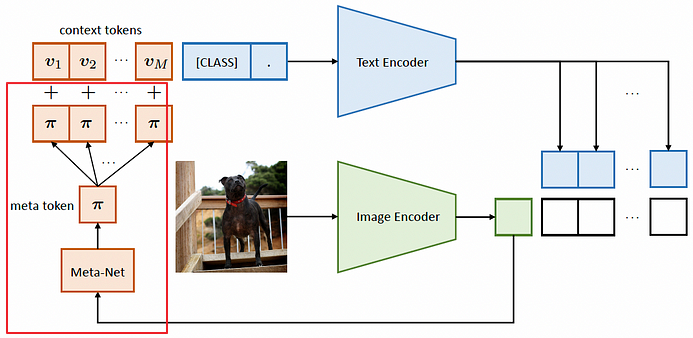
CoOp에서 Meta-Net 부분 추가됨
Unified Text Prompting / Deep Text Prompting 등에 대해 추가 확장을 통해 VCP-CLIP 등의 논문으로 확장
댓글